





Hadoop培训课程:Chukwa搭建、安装、部署、应用
最新学讯:近期OCP认证正在报名中,因考试人员较多请尽快报名获取最近考试时间,报名费用请联系在线老师,甲骨文官方认证,报名从速!
我要咨询Hadoop培训课程:Chukwa搭建、安装、部署、应用
1、搭建环境
部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放Hadoop等组件运行包。因为该目录用于安装Hadoop等组件程序,用户对shiyanlou必须赋予rwx权限(一般做法是root用户在根目录下创建/app目录,并修改该目录拥有者为shiyanlou(chown –R shiyanlou:shiyanlou /app)。
Hadoop搭建环境:
l 虚拟机操作系统: CentOS6.6 64位,单核,1G内存
l JDK:1.7.0_55 64位
l Hadoop:1.1.2
2、Chukwa介绍
chukwa 是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在 Hadoop 的 hdfs 和 map/reduce 框架之上的,继承了 Hadoop 的可伸缩性和鲁棒性。Chukwa 还包含了一个强大和灵活的工具集,可用于展示、监控和分析已收集的数据。
2.1 Chukwa架构

其中主要的组件为:
1. agents :负责采集最原始的数据,并发送给 collectors
2. adaptor :直接采集数据的接口和工具,一个 agent 可以管理多个 adaptor 的数据采集
3. collectors :负责收集 agents 收送来的数据,并定时写入集群中
4. map/reduce jobs :定时启动,负责把集群中的数据分类、排序、去重和合并
5. HICC :负责数据的展示
2.2 组件说明
l adaptors 和 agents
在每个数据的产生端(基本上是集群中每一个节点上), chukwa 使用一个 agent 来采集它感兴趣的数据,每一类数据通过一个 adaptor 来实现, 数据的类型(DataType?)在相应的配置中指定. 默认地, chukwa 对以下常见的数据来源已经提供了相应的 adaptor : 命令行输出、log 文件和 httpSender等等. 这些 adaptor 会定期运行(比如每分钟读一次 df 的结果)或事件驱动地执行(比如 kernel 打了一条错误日志). 如果这些 adaptor 还不够用,用户也可以方便地自己实现一个 adaptor 来满足需求。
为防止数据采集端的 agent 出现故障,chukwa 的 agent 采用了所谓的 ‘watchdog’ 机制,会自动重启终止的数据采集进程,防止原始数据的丢失。另一方面, 对于重复采集的数据, 在 chukwa 的数据处理过程中,会自动对它们进行去重. 这样,就可以对于关键的数据在多台机器上部署相同的 agent,从而实现容错的功能.
l collectors
agents 采集到的数据,是存储到 Hadoop 集群上的. Hadoop 集群擅长于处理少量大文件,而对于大量小文件的处理则不是它的强项,针对这一点,chukwa 设计了 collector 这个角色,用于把数据先进行部分合并,再写入集群,防止大量小文件的写入。
另一方面,为防止 collector 成为性能瓶颈或成为单点,产生故障, chukwa 允许和鼓励设置多个 collector, agents 随机地从collectors 列表中选择一个collector 传输数据,如果一个 collector 失败或繁忙,就换下一个collector。从而可以实现负载的均衡,实践证明,多个 collector 的负载几乎是平均的.
l demux 和 archive
放在集群上的数据,是通过 map/reduce 作业来实现数据分析的. 在 map/reduce 阶段, chukwa 提供了 demux 和 archive 任务两种内置的作业类型.
demux 作业负责对数据的分类、排序和去重. 在 agent 一节中,我们提到了数据类型(DataType)的概念.由 collector 写入集群中的数据,都有自己的类型. demux 作业在执行过程中,通过数据类型和配置文件中指定的数据处理类,执行相应的数据分析工作,一般是把非结构化的数据结构化,抽取中其中的数据属性.由于 demux 的本质是一个 map/reduce 作业,所以我们可以根据自己的需求制定自己的 demux 作业,进行各种复杂的逻辑分析. chukwa 提供的demux interface 可以用 java 语言来方便地扩展.
而 archive 作业则负责把同类型的数据文件合并,一方面保证了同一类的数据都在一起,便于进一步分析, 另一方面减少文件数量, 减轻 Hadoop 集群的存储压力。
l dbadmin
放在集群上的数据,虽然可以满足数据的长期存储和大数据量计算需求,但是不便于展示.为此, chukwa 做了两方面的努力:
1. 使用 mdl 语言,把集群上的数据抽取到 mysql 数据库中,对近一周的数据,完整保存,超过一周的数据,按数据离当前时间长短作稀释,离当前越久的数据,所保存的数据时间间隔越长.通过 mysql 来作数据源,展示数据.
2. 使用 hbase 或类似的技术,直接把索引化的数据在存储在集群上
到 chukwa 0.4.0 版本为止, chukwa 都是用的第一种方法,但是第二种方法更优雅也更方便一些.
l hicc
hicc 是 chukwa 的数据展示端的名称。在展示端,chukwa 提供了一些默认的数据展示 widget,可以使用“列表”、“曲线图”、“多曲线图”、“柱状图”、“面积图式展示一类或多类数据,给用户直观的数据趋势展示。而且,在 hicc 展示端,对不断生成的新数据和历史数据,采用 robin 策略,防止数据的不断增长增大服务器压力,并对数据在时间轴上“稀释”,可以提供长时间段的数据展示
从本质上, hicc 是用 jetty 来实现的一个 web 服务端,内部用的是 jsp 技术和 javascript 技术.各种需要展示的数据类型和页面的局都可以通过简直地拖拽方式来实现,更复杂的数据展示方式,可以使用 sql 语言组合出各种需要的数据.如果这样还不能满足需求,不用怕,动手修改它的 jsp 代码就可以了
3、安装部署Chukwa
3.1 Chukwa部署过程
3.1.1 下载Chukwa
可以到apache基金chukwa官网http://chukwa.apache.org/,选择镜像下载地址http://mirrors.hust.edu.cn/apache/chukwa/下载一个稳定版本,如下图所示下载chukwa-0.6.0.tar.gz

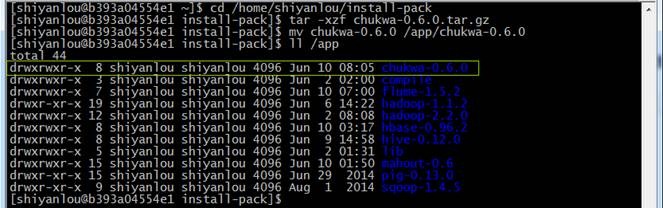
也可以在/home/shiyanlou/install-pack目录中找到该安装包,解压该安装包并把该安装包复制到/app目录中
cd /home/shiyanlou/install-pack
tar -xzf chukwa-0.6.0.tar.gz
mv chukwa-0.6.0 /app/chukwa-0.6.0
3.1.2 设置/etc/profile参数
编辑/etc/profile文件,声明chukwa的home路径和在path加入bin/sbin的路径:
export CHUKWA_HOME=/app/chukwa-0.6.0
export CHUKWA_CONF_DIR=$CHUKWA_HOME/etc/chukwa
export PATH=$PATH:$CHUKWA_HOME/bin:$CHUKWA_HOME/sbin

编译配置文件/etc/profile,并确认生效
source /etc/profile
echo $PATH
3.1.3 将Chukwa文件复制到Hadoop中
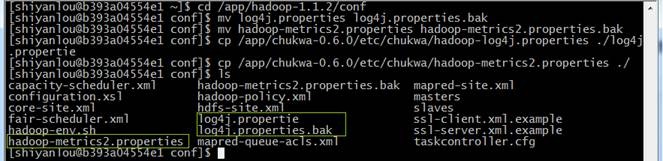
首先把Hadoop配置目录中的log4j.properties和Hadoop-metrics2.properties文件改名备份,然后把chukwa配置目录中的log4j.properties和Hadoop-metrics2.properties文件复制到Hadoop配置目录中。
cd /app/hadoop-1.1.2/conf
mv log4j.properties log4j.properties.bak
mv Hadoop-metrics2.properties Hadoop-metrics2.properties.bak
cp /app/chukwa-0.6.0/etc/chukwa/hadoop-log4j.properties ./log4j.propertie
cp /app/chukwa-0.6.0/etc/chukwa/hadoop-metrics2.properties ./
3.1.4 将Chukwa中jar复制到Hadoop中
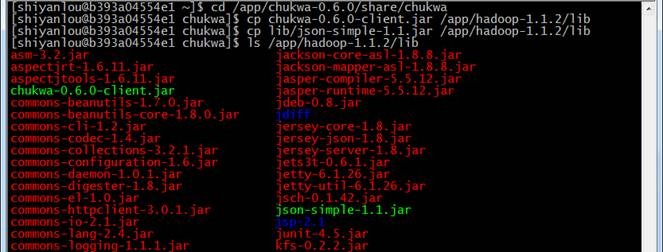
把chukwa中的chukwa-0.6.0-client.jar和json-simple-1.1.jar两个jar文件复制到Hadoop中lib目录下:
cd /app/chukwa-0.6.0/share/chukwa
cp chukwa-0.6.0-client.jar /app/hadoop-1.1.2/lib
cp lib/json-simple-1.1.jar /app/hadoop-1.1.2/lib
ls /app/hadoop-1.1.2/lib
3.1.5 修改chukwa-config.sh
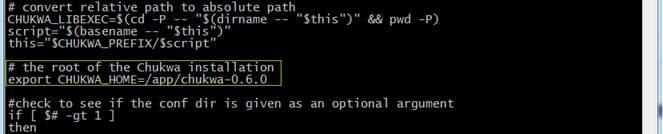
打开$CHUKWA_HOME/libexec/chukwa-config.sh文件
cd /app/chukwa-0.6.0/libexec
sudo vi chukwa-config.sh
将export CHUKWA_HOME='pwd -P ${CHUKWA_LIBEXEC}/..' 改为chukwa的安装目录:
export CHUKWA_HOME=/app/chukwa-0.6.0
3.1.6 修改chukwa-env.sh
打开$CHUKWA_HOME/etc/chukwa/chukwa-env.sh文件
cd /app/chukwa-0.6.0/etc/chukwa/
sudo vi chukwa-env.sh
配置JAVA_HOME和HADOOP_CONF_DIR等变量
# The java implementation to use. Required.
export JAVA_HOME=/app/lib/jdk1.7.0_55/
# Hadoop Configuration directory
export HADOOP_CONF_DIR=/app/hadoop-1.1.2/conf
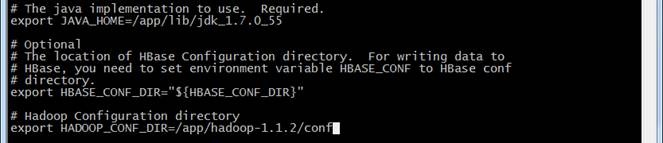
编译配置文件chukwa-env.sh使之生效
3.1.7 修改collectors文件
打开$CHUKWA_HOME/etc/chukwa/collectors文件
cd /app/chukwa-0.6.0/etc/chukwa/
sudo vi collectors
该配置指定哪台机器运行收集器进程,例如修改为http://hadoop:8080,指定Hadoop机器运行收集器进程

3.1.8 修改initial_adaptors文件
打开$CHUKWA_HOME/etc/chukwa/initial_adaptors文件
cd /app/chukwa-0.6.0/etc/chukwa/
sudo vi initial_adaptors
可以使用默认配置(即不需要修改)
为了更好显示测试效果这里添加新建的监控服务,监控/app/chukwa-0.6.0/目录下的testing文件变化情况
add filetailer.FileTailingAdaptor FooData /app/chukwa-0.6.0/testing 0

建立被监控testing文件
cd /app/chukwa-0.6.0
touch testing

3.1.9 修改chukwa-collector-conf.xml文件
1. 打开$CHUKWA_HOME/etc/chukwa/chukwa-collector-conf.xml文件
cd /app/chukwa-0.6.0/etc/chukwa/
sudo vi chukwa-collector-conf.xml
2. 启用chukwaCollector.pipeline参数
chukwaCollector.pipeline
org.apache.Hadoop.chukwa.datacollection.writer.SocketTeeWriter,org.apache.Hadoop.chukwa.datacollection.writer.SeqFileWriter

3. 注释hbase的参数(如果要使用hbase则不需要注释)

4. 指定HDFS的位置为 hdfs://hadoop1:9000/chukwa/logs
<property>
<name>writer.hdfs.filesystem</name>
<value>hdfs://hadoop:9000</value>
<description>HDFS to dump to</description>
</property>
<property>
<name>chukwaCollector.outputDir</name>
<value>/chukwa/logs/</value>
<description>Chukwa data sink directory</description>
</property>

5. 确认默认情况下collector监听8080端口

3.1.10 配置Agents文件
打开$CHUKWA_HOME/etc/chukwa/agents文件
cd /app/chukwa-0.6.0/etc/chukwa/
sudo vi agents
编辑$CHUKWA_CONF_DIR/agents文件,使用Hadoop

3.1.11 修改chukwa-agent-conf.xml文件
打开$CHUKWA_HOME/etc/chukwa/chukwa-agent-conf.xml文件
cd /app/chukwa-0.6.0/etc/chukwa/
sudo vi chukwa-agent-conf.xml
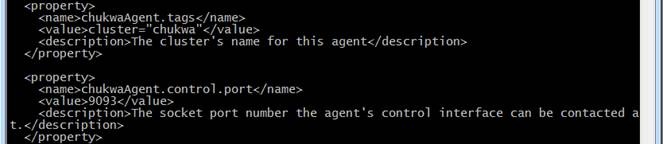
$CHUKWA_CONF_DIR/chukwa-agent-conf.xml文件维护了代理的基本配置信息,其中最重要的属性是集群名,用于表示被监控的节点,这个值被存储在每一个被收集到的块中,用于区分不同的集群,如设置cluster名称:cluster="chukwa" ,使用默认值即可:
<property>
<name>chukwaAgent.tags</name>
<value>cluster="chukwa"</value>
<description>The cluster's name for this agent</description>
</property>
3.2 Chukwa部署验证
3.2.1 启动Chukwa
分别启动如下进程:
1. 启动Hadoop
cd /app/hadoop-1.1.2/bin
./start-all.sh
jps

2. 启动chukwa:
cd /app/chukwa-0.6.0/sbin
./start-chukwa.sh
./start-collectors.sh
./start-data-processors.sh

使用jps查看启动状态:

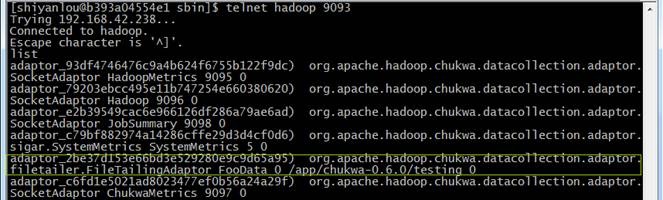
使用telnet查看agent启动情况
telnet Hadoop 9093
telnet>list
3.2.2 准备日志数据文件和添加数据脚本
1. 在/app/chukwa-0.6.0/testdata/目录下创建weblog文件,内容如下:
cd /app/chukwa-0.6.0
mkdir testdata
cd testdata
vi weblog
数据如下:
220.181.108.151 [31/Jan/2012:00:02:32] "GET /home.php?mod=space"
208.115.113.82 [31/Jan/2012:00:07:54] "GET /robots.txt"
220.181.94.221 [31/Jan/2012:00:09:24] "GET /home.php?mod=spacecp"
112.97.24.243 [31/Jan/2012:00:14:48] "GET /data/common.css?AZH HTTP/1.1"
112.97.24.243 [31/Jan/2012:00:14:48] "GET /data/auto.css?AZH HTTP/1.1"
112.97.24.243 [31/Jan/2012:00:14:48] "GET /data/display.css?AZH HTTP/1.1"
220.181.108.175 [31/Jan/2012:00:16:54] "GET /home.php"
220.181.94.221 [31/Jan/2012:00:19:15] "GET /?72 HTTP/1.1" 200 13614 "-"
218.5.72.173 [31/Jan/2012:00:21:39] "GET /forum.php?tid=89 HTTP/1.0"
65.52.109.151 [31/Jan/2012:00:24:47] "GET /robots.txt HTTP/1.1"
220.181.94.221 [31/Jan/2012:00:26:12] "GET /?67 HTTP/1.1"
218.205.245.7 [31/Jan/2012:00:27:16] "GET /forum-58-1.html HTTP/1.0"
2. 在/app/chukwa-0.6.0/testdata/目录下创建weblogadd.sh执行脚本,该脚本执行往3.3.11创建/app/chukwa-0.6.0/testing文件添加weblog数据:
cd /app/chukwa-0.6.0/testdata/
vi weblogadd.sh
内容为:
cat /app/chukwa-0.6.0/testdata/weblog >> /app/chukwa-0.6.0/testing

3.2.3 查看HDFS的文件
启动chukwa的agents和collector,然后运行weblogadd.sh脚本,往weblog文件中添加数据,最后查看HDFS的/chukwa/logs目录下监听生成的数据文件
cd /app/chukwa-0.6.0/testdata
sudo sh ./weblogadd.sh
Hadoop fs -ls /chukwa/logs










