





Hadoop�����̳̣�Hadoop�İ�װ����
����ѧѶ������OCP��֤���ڱ����У�������Ա�϶��뾡�챨����ȡ�������ʱ�䣬������������ϵ������ʦ�����Ĺٷ���֤���������٣�
��Ҫ��ѯHadoop�������ֲ���ʽ������ģʽ��α�ֲ�ģʽ����Ⱥģʽ;���ΰ�װ������α�ֲ�ģʽΪ��������һ̨������������Hadoop(����Ƿֲ�ʽģʽ��������Ҫ����Master���ڵ㣬�������Slave�ӽڵ�)������˵����������˵����Ĭ��ʹ��root�û���¼���ڵ㣬�������µ�һϵ�����á�
��װ����ǰ������������������
vmware workstation 8.0�����ϰ汾
redhat server 6.x�汾��centos 6.x�汾
jdk-6u24-linux-xxx.bin
Hadoop-1.1.2.tar.gz
���þ�̬IP��ַ
����ģʽ�¿���ִ��setup����������ý������þ�̬IP��ַ;x-window�����¿����һ�����ͼ������;
������ɺ�ִ��service network restart���������������;
��֤��ִ������ifconfig
��������
<1>�ĵ�ǰ�Ự�е�������(�����ҵ���������ΪHadoop-master)��ִ������hostname Hadoop-master
<2>�������ļ��е���������ִ������vi /etc/sysconfig/network
��֤������ϵͳreboot
DNS��
ִ������vi /etc/hosts,����һ�����ݣ�����(�����ҵ�Master�ڵ�IP���õ�Ϊ192.168.80.100)��
192.168.80.100 Hadoop-master
������˳�
��֤��ping Hadoop-master
�رշ���ǽ�����Զ�����
<1>ִ�йرշ���ǽ���service iptables stop
��֤��service iptables stauts
<2>ִ�йرշ���ǽ�Զ��������chkconfig iptables off
��֤��chkconfig --list | grep iptables
SSH(Secure Shell)���������¼
<1>ִ�в�����Կ���ssh-keygen �Ct rsa��λ���û�Ŀ¼�µ�.ssh�ļ���(.sshΪ�����ļ�������ͨ��ls �Ca�鿴)
<2>ִ�в������cp id_rsa.pub authorized_keys
��֤��ssh localhost
����JDK��Hadoop-1.1.2.tar.gz��Linux��
<1>ʹ��WinScp��CuteFTP�ȹ��߽�jdk��Hadoop.tar.gz���Ƶ�Linux��(���踴�Ƶ���Downloads�ļ�����);
<2>ִ�����rm �Crf /usr/local/* ɾ�����ļ����������ļ�
<3>ִ�����cp /root/Downloads/* /usr/local/ ���临�Ƶ�/usr/local/�ļ�����
��װJDK
<1>��/usr/local�½�ѹjdk��װ�ļ���./jdk-6u24-linux-i586.bin(�����Ȩ�������ʾ������Ϊ��ǰ�û��Դ�jdk����ִ��Ȩ�ޣ�chmod u+x jdk-6u24-linux-i586.bin)
<2>��������ѹ���jdk�ļ��У�mv jdk1.6.0_24 jdk(�˲��շDZ�Ҫ��ֻ�ǽ���)
<3>����Linux����������vi /etc/profile�����������Ӽ��У�
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
<4>��Ч�����������ã�source /etc/profile
��֤��java �Cversion
��װHadoop
<1>��/usr/local�½�ѹHadoop��װ�ļ�:tar �Czvxf Hadoop-1.1.2.tar.gz
<2>��ѹ��������Hadoop-1.1.2�ļ��У�mv Hadoop-1.1.2 Hadoop(�˲��շDZ�Ҫ��ֻ�ǽ���)
<3>����Hadoop��ػ���������vi /etc/profile������������һ�У�
export HADOOP_HOME=/usr/local/hadoop
Ȼ����һ�У�
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME:$PATH
<4>������������source /etc/profile
<5>��Hadoop�������ļ�������λ��$HADOOP_HOME/confĿ¼�¡�
�ֱ����ĸ������ļ���Hadoop-env.sh��core-site.xml��hdfs-site.xml��mapred-site.xml;
���������������£�(���������ݽ϶࣬����ʹ��WinScp�������Ŀ¼�½��б༭�ͱ��棬���Խ�ʡ�϶�ʱ��;���)
5.1��Hadoop-env.sh�� �ĵھ��У�
export JAVA_HOME=/usr/local/jdk/
���������ڴ����1G������Ҫ��HADOOP_HEAPSIZE(Ĭ��Ϊ1000)��ֵ��
export HADOOP_HEAPSIZE=100
5.2��core-site.xml�� ��configuration��������������(���е�Hadoop-masterΪ�����õ�������)��
fs.default.name
hdfs://hadoop-master:9000
change your own hostname
Hadoop.tmp.dir
/usr/local/hadoop/tmp
5.3 ��hdfs-site.xml�� ��configuration�������������ݣ�
dfs.replication
1
dfs.permissions
false
5.4 ��mapred-site.xml�� ��configuration��������������(���е�Hadoop-masterΪ�����õ�������)��
mapred.job.tracker
Hadoop-master:9001
change your own hostname
<6>ִ�������Hadoop���г�ʼ��ʽ����Hadoop namenode �Cformat
<7>ִ����������Hadoop��start-all.sh(һ�����������н���)
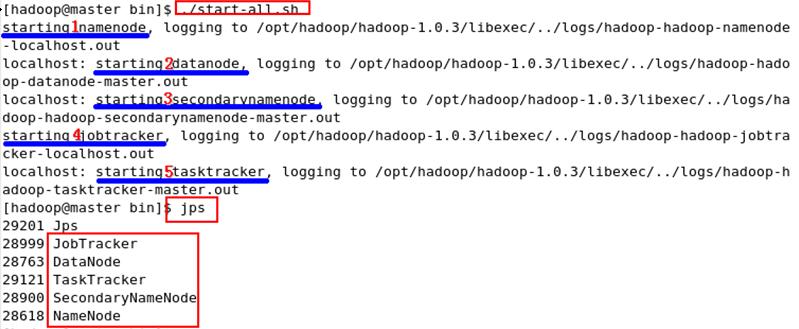
�ڶ��ַ�ʽ��ͨ��ִ�����·�ʽ���������HDFS��MapReduce��start-dfs.sh��start-mapred.sh������stop-dfs.sh��stop-mapred.sh�ر�;
�����ַ�ʽ��ͨ��ִ�����·�ʽ����ֱ������������̣�
Hadoop-daemon.sh start namenode
Hadoop-daemon.sh start datanode
Hadoop-daemon.sh start secondarynamenode
Hadoop-daemon.sh start jobtracker
Hadoop-daemon.sh start tasktracker
���ַ�ʽ��ִ��������Hadoop-daemon.sh start [��������]������������ʽ�ʺ��ڵ������ӡ�ɾ���ڵ��������ڰ�װ��Ⱥ������ʱ��ῴ����
��֤��
�� ִ��jps����鿴java������Ϣ�������start-all.sh��һ����ʾ5��java���̡�
��������������Hadoop������URL��Hadoop-master:50070��Hadoop-master:50030���������������Windows�����������ֱ��ͨ��ip��ַ�Ӷ˿ںŷ��ʣ�Ҳ��������C����System32/drivers/etc/�е�hosts�ļ�������DNS������ӳ�䣬���磺192.168.80.100 Hadoop-master��
����Ч������ͼ��
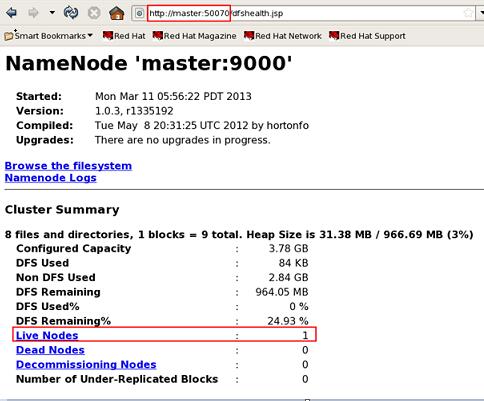
namenode
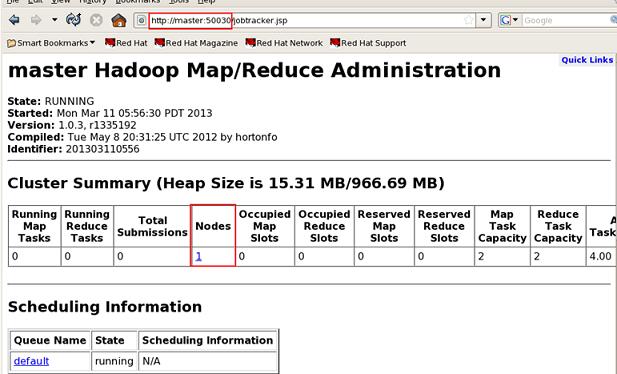
jobtracker
<8>NameNode����û�������ɹ�?���Դ����¼��������飺
û�ж�NameNode���и�ʽ��������Hadoop namenode �Cformat(PS����θ�ʽ��Ҳ����������ղ�������ɾ��/usr/local/hadoop/tmp�ļ��������¸�ʽ��)
Hadoop�����ļ�ֻ����û�ģ� ���ĸ������ļ���Ҫ�ĵIJ���
DNSû������IP��hostname�İ�vi /etc/hosts
SSH���������¼û�����óɹ�����������rsa��Կ
<9>Hadoop���������г������¾���?
��root@Hadoop local��# start-all.sh
����ͨ�����²���ȥ���þ�����Ϣ��
������ִ������鿴shell�ű���vi start-all.sh(��binĿ¼��ִ��)�����Կ�������ͼ��ʾ�Ľű�
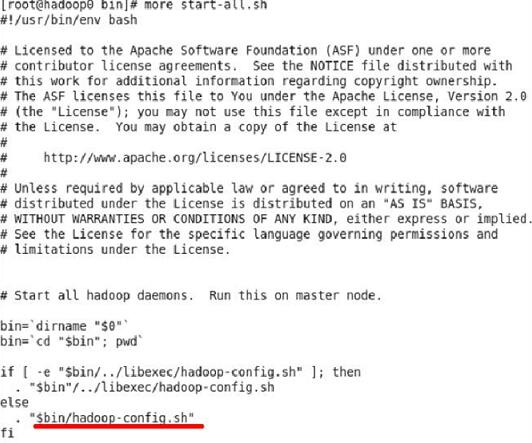
��Ȼ���ǿ�����shell�ű���������ǿ��Բµ����ܺ��ļ�Hadoop-config.sh�йأ������ٿ�һ������ļ���Դ�롣ִ�����vi Hadoop-config.sh(��binĿ¼��ִ��)�����ڸ��ļ��ش�����ֻ��ȡ���һ���֣�����ͼ��
��ͼ�еĺ�ɫ����п��Կ������ű��жϻ�������HADOOP_HOME��HADOOP_HOME_WARN_SUPPRESS��ֵ�����ǰ��Ϊ�գ����߲�Ϊ�գ�����ʾ������Ϣ��Warning??����
������ǰ��İ�װ�������Ѿ�������HADOOP_HOME���������������ˣ�ֻ��Ҫ��HADOOP_HOME_WARN_SUPPRESS����һ��ֵ�Ϳ����ˡ����ԣ�ִ�����vi /etc/profile������һ������(ֵ�������һ�����ɣ�������Ϊ0)��
export HADOOP_HOME_WARN_SUPPRESS=0
�����˳���ִ��������Ч���source /etc/profile����Ч����������Hadoop��������ʾ������Ϣ�ˡ�
���ˣ�һ��Hadoop��Master�ڵ�İ�װ���ý���������������Ҫ���дӽڵ�����á�

����ԤԼ ���ȱ��� ��ȡ�γ�����

- Ƚ�˸�-��ʦCUUG���ƽ�ʦ
- Ƚ��ʦ CUUG���ƽ�ʦ Oracle��RedHat����ʦ��Unix/Linux ����ר��...[��ϸ�˽���ʦ]

- ������-��ʦCUUG���ƽ�ʦ
- ����ʦ CUUG���ƽ�ʦ ��ͨOracle���������ݻָ��������Ż� 11��Ora...[��ϸ�˽���ʦ]






