





Hadoop入门教程:Hadoop简介,什么是Hadoop
最新学讯:近期OCP认证正在报名中,因考试人员较多请尽快报名获取最近考试时间,报名费用请联系在线老师,甲骨文官方认证,报名从速!
我要咨询Hadoop入门教程:Hadoop简介,什么是Hadoop?从这种渊源上来讲,Hadoop本质上起源于Google的集群系统,Google的数据中心使用廉价的Linux PC机组成集群,用其运行各种应用。
即使是分布式开发的新手也可以迅速使用Google的基础设施。Google采集系统的核心的组件有两个:第一个就是GFS(Google FileSystem),一个分布式文件系统,隐藏下层负载均衡,冗余复制等细节,对上层程序提供一个统一的文件系统API接口;第二个是MapReduce计算模型,Google发现大多数分布式运算可以抽象为MapReduce操作。Map是把输入Input分解成中间的Key/Value对,Reduce把Key/Value合成最终输出Output。这两个函数由程序员提供给系统,下层设施把Map和Reduce操作分布在集群上运行,并把结果存储在GFS上。
而Hadoop就是Google集群系统的一个Java开源实现,是一个项目的总称,主要是由HDFS、MapReduce组成。其中HDFS是Google File System(GFS)的开源实现;MapReduce是Google MapReduce的开源实现。这个分布式框架很有创造性,而且有极大的扩展性,使Google在系统吞吐量上有很大的竞争力。在2006年时Hadoop就受到了Yahoo的支持,目前Yahoo内部已经使用Hadoop代替了原来的分布式系统并拥有了世界上最大的Hadoop集群。
Hadoop实现了HDFS文件系统和MapReduce,使Hadoop成为一个分布式的计算平台。用户只要分别实现Map和Reduce,并注册Job即可自动分布式运行。因此,Hadoop并不仅仅是一个用于存储的分布式文件系统,而是用于由通用计算设备组成的大型集群上执行分布式应用的框架。一般来讲,狭义的Hadoop就是指HDFS和MapReduce,是一种典型的Master-Slave架构,如图1-1所示。
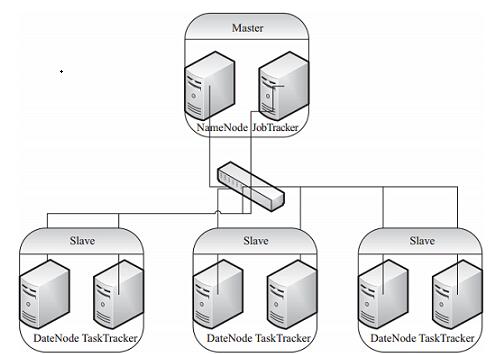
从图1-1中可以看到,典型的Hadoop由一个Master逻辑节点和多个Slave逻辑节点构成,Master逻辑节点由NameNode和JobTracker组成,NameNode是HDFS的Master,主要负责Hadoop分布式文件系统元数据的管理工作;JobTracker是MapReduce的Master,其主要职责就是启动、跟踪、调度各个TaskTracker的任务执行,每一个Slave逻辑节点通常同时具有DataNode以及TaskTracker的功能。TaskTracker根据应用要求来结合本地数据执行Map任务及Reduce任务。
如今广义的Hadoop其实已经包括Hadoop本身和基于Hadoop的开源项目,并且已经形成了完备的Hadoop生态链系统,如图1-2所示。
在图1-2中系统之间的联系使用箭头来表示,各系统简介如下:
HDFS――Hadoop分布式文件系统,GFS的Java开源实现,运行于大型商用机器集群,可实现分布式存储。
MapReduce――一种并行计算框架,Google MapReduce模型的Java开源实现,基于其写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理T级别及以上的数据集。
Zookeeper――分布式协调系统,Google Chubby的Java开源实现,是高可用的和可靠的分布式协同(coordination)系统,提供分布式锁之类的基本服务,用于构建分布式应用。
Hbase――基于Hadoop的分布式数据库,Google BigTable的开源实现,是一个有序、稀疏、多维度的映射表,有良好的伸缩性和高可用性,用来将数据存储到各个计算节点上。
Hive――是为提供简单的数据操作而设计的分布式数据仓库,它提供了简单的类似SQL语法的HiveQL语言进行数据查询。
Cloudbase――基于Hadoop的数据仓库,支持标准的SQL语法进行数据查询。
Pig――大数据流处理系统,建立于Hadoop之上为并行计算环境提供了一套数据工作流语言和执行框架。
Mahout――基于HadoopMapReduce的大规模数据挖掘与机器学习算法库。
Oozie――MapReduce工作流管理系统。
Sqoop――数据转移系统,是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库中的数据导入Hadoop的HDFS中,也可以将HDFS的数据导入关系型数据库中。
Flume――一个可用的、可靠的、分布式的海量日志采集、聚合和传输系统。
Scribe――Facebook开源的日志收集聚合框架系统。
图1-2中的RDBMS是传统的关系数据库系统,通过Sqoop就可以和Hadoop生态系统集成。










